Hamming und lineare Codes
Einführung
Die Funkkommunikation im Feld kann gewissermaßen als “verrauschter Kommunikationskanal” mit Störungen durch andere Signale, Fading usw. modelliert werden. Das bedeutet, dass die Empfangswahrscheinlichkeit ständig von den Emissionen anderer Geräte in der Nähe und der Lage von Hindernissen beeinflusst wird. Bei analogen Übertragungen, z. B. Sprache und Musik, ist die Verschlechterung des Signal-Rausch-Verhältnisses als Rauschen über der Sprache oder Musik zu hören, das nicht unterdrückt werden kann.
Bei der Übertragung von Daten (z. B. eines Bitstroms von einer seriellen Schnittstelle) können Störungen dazu führen, dass ein Empfänger z. B. eine Null ausgibt, obwohl eine Eins übertragen wurde (ein Bitfehler). Datenkommunikation kann im Gegensatz zu Sprache nicht einfach so übertragen werden. Das liegt daran, dass ein einziger Bitfehler aufgrund von Störungen zu einer falschen Aktion führen kann.
Fehlererkennung versus Fehlerkorrektur
Abhängig von der Komplexität der Kommunikationsbedingungen und dem verwendeten Kodierungsverfahren (von denen es viele gibt), kann ein Empfänger Bitfehler erkennen und in manchen Fällen korrigieren. Wenn ein Empfänger das Vorhandensein eines Bitfehlers feststellen kann, aber nicht die Position, handelt es sich um eine reine Fehlererkennung. In diesen Fällen kann ein Empfänger die Daten zurückweisen oder, wenn es sich um zyklische (sich wiederholende) Daten handelt, auf die nächsten Daten warten. Oder der Empfänger kann den Sender auffordern, die Daten erneut zu senden, aber dazu wäre eine bidirektionale Kommunikation erforderlich, was die Komplexität der Hardware erhöht.
Wenn die Positionen der Bitfehler bekannt sind (und da ein Bit nur die Werte 0 und 1 annehmen kann), kann der Empfänger die Daten automatisch wiederherstellen, indem er die betroffenen Bits umdreht (Fehlererkennung und Fehlerkorrektur), und die Kommunikation kann ohne Unterbrechungen fortgesetzt werden. Der Empfänger muss nicht eine erneute Übermittlung anfordern, so dass keine bidirektionale Kommunikation erforderlich ist.
Unabhängig vom verwendeten Kodierungsverfahren werden der Nachricht immer redundante Bits hinzugefügt, die die effektive Bitrate des Kanals senken.
Blockcodes
Kodierungsverfahren können je nach Art der Kodierung der Nachrichtenbits bei Hinzufügen von Redundanz in verschiedene Kategorien eingeteilt werden. Wenn die Bits in der Nachricht einzeln kodiert werden, spricht man von Faltungskodierung, und die Ausgabe ist ein kontinuierlicher Bitstrom.
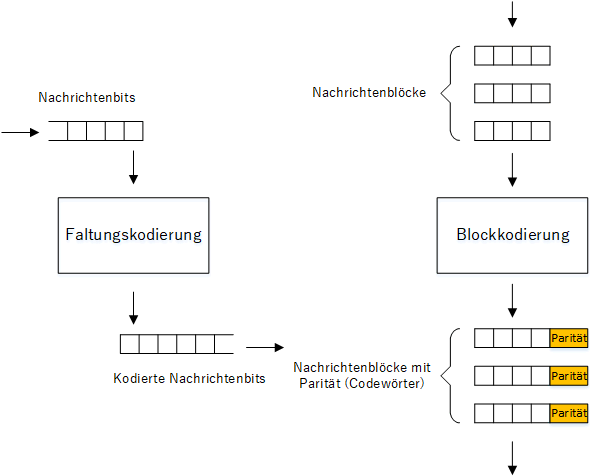
Faltung versus Blockkodierung
In diesem Artikel konzentrieren wir uns jedoch auf die Blockkodierung, d. h. die Gruppierung von Nachrichtenbits in Blöcke und deren Kodierung als einzelne Blöcke. Während des Empfangs kann der Empfänger die Paritätsbits prüfen und feststellen, ob das empfangene Codewort Fehler enthält.
Systematische Codewörter
Wenn die Paritätsbits hinzugefügt werden, aber die ursprünglichen Nachrichtenbits im Codewort verbleiben, spricht man von systematischen Codewörtern. Wir werden in diesem Artikel systematische Codewörter als Beispiele verwenden.
Lineare Codewörter
Das Ergebnis der Blockkodierung bedeutet, dass wir alle unsere Nachrichten auf ihre entsprechenden Codewörter abbilden. Also lassen Sie uns all diese Codewörter in einer Tabelle wie folgt auflisten:
| Codeworttabelle | |
|---|---|
| A | .. |
| .. | .. |
| .. | C |
| .. | .. |
| B | .. |
| .. | .. |
Stellen Sie sich vor, Sie wählen zwei beliebige Codewörter aus, A und B. Dann führen Sie die bitweise XOR-Addition an beiden durch, und wir nennen das Ergebnis C. Für diejenigen, die mit der XOR-Addition nicht vertraut sind, können wir sie formell wie folgt schreiben:
$$A \oplus B= C$$
*(zur Erinnerung an die XOR-Addition: 0⊕0 = 0, 0⊕1 = 1, 1⊕0 = 1, 1⊕1 = 0, die XOR-Verknüpfung von geraden Einsen ergibt eine Null und von ungeraden Einsen eine Eins)
Zum Beispiel, wenn A = 0110 und B = 1100.
$$
\require{enclose}
\begin{array}{r}
0110 \\[-3pt]
\oplus\underline{1100}\\
1010
\end{array}
$$
Dann wäre C gleich 1010. Nun stellen wir fest, dass C als weiteres Codewort in der Tabelle auftaucht. Wenn wir den Vorgang mit allen Kombinationen von A- und B-Codewörtern wiederholen und das Ergebnis immer ein anderes Codewort in der Tabelle wäre, dann werden alle Codewörter in der Tabelle als linear bezeichnet. Wir werden sehen, wie lineare Codewörter die Berechnung der minimalen Hamming-Distanz, dmin, erleichtern.
Hamming- und Matrizenbegriffe / Notation
Matrizen
Um das Beispiel in diesem Artikel zu verstehen, muss man sich mit Matrizen auskennen.
Dimension einer Matrix
Die Dimension einer Matrix wird durch Höhe x Breite ausgedrückt. Zum Beispiel:
$$
\text{3 x 2 Matrix =}
\begin{bmatrix}
1 & 0 \\
1 & 0 \\
1 & 1 \\
\end{bmatrix}
$$
Identitätsmatrix
Eine Identitätsmatrix (In) ist eine quadratische Matrix, die an allen Diagonalen Einsen und an anderen Stellen Nullen hat. Zum Beispiel:
$$
I_1 =
\begin{bmatrix}
1 \\
\end{bmatrix}
$$
$$
I_2 =
\begin{bmatrix}
1 & 0 \\
0 & 1 \\
\end{bmatrix}
$$
$$
I_3 =
\begin{bmatrix}
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \\
\end{bmatrix}
$$
Eine Matrix, die mit einer Identitätsmatrix multipliziert wird (siehe Matrizenmultiplikation unten), lässt die Ausgangsmatrix unverändert. Dies ist vergleichbar mit der Multiplikation einer Zahl mit Eins.
Transposition
Das Transponieren einer Matrix bedeutet, dass die Zeilen und Spalten vertauscht werden. Die Matrix, die transponiert wurde, wird als MT geschrieben. Zum Beispiel:
$$
M =
\begin{bmatrix}
\color{red}{1} & \color{red}{0} & \color{red}{0} \\
1 & 1 & 0 \\
0 & 1 & 1 \\
\end{bmatrix}
$$
$$
M^T =
\begin{bmatrix}
\color{red}{1} & 1 & 0 \\
\color{red}{0} & 1 & 1 \\
\color{red}{0} & 0 & 1 \\
\end{bmatrix}
$$
Matrizenmultiplikation
\(
\begin{bmatrix}
\color{red}{0} & \color{red}{1} & \color{red}{0} \\
\end{bmatrix}
\begin{bmatrix}
\color{green}{0} & 0 & 1 \\
\color{green}{1} & 1 & 0 \\
\color{green}{1} & 0 & 0 \\
\end{bmatrix}
=
\begin{bmatrix}
(\color{red}{0}×\color{green}{0})\oplus(\color{red}{1}×\color{green}{1})\oplus(\color{red}{0}×\color{green}{1}) & 1 & 0 \\
\end{bmatrix}
=
\begin{bmatrix}
1 & 1 & 0 \\
\end{bmatrix}
\)
Bei der Matrizenmultiplikation wird die Zeile der ersten Matrix mit der Spalte der zweiten Matrix multipliziert. Kombinieren Sie dann mit XOR-Addition, um das erste Glied des Ergebnisses zu erhalten. Gehen Sie anschließend zur zweiten Spalte der zweiten Matrix über und wiederholen Sie den Vorgang.
Länge des Codeworts (n)
Wenn die Nachrichtenblöcke in Codewörter umgewandelt werden, hat jedes Codewort eine feste Länge, nämlich n Bits. Die Anzahl der möglichen Codewörter beträgt dann 2n.
Länge der Nachricht (k)
Jede Nachricht hat eine Länge von k Bits. Es ist hoffentlich klar, dass wir 2k von 2n möglichen Codewörtern zuweisen müssen, um unsere gültige Codeworttabelle zu erstellen. Die nicht zugewiesenen Codewörter, die 2n – 2k entsprechen, werden als ungültige Codewörter betrachtet, wenn der Empfänger sie sieht.
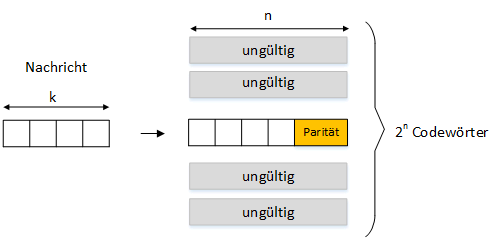
Zuordnung von Nachrichten zu Codewörtern
Generatormatrix (G)
Um unsere Nachricht in ein lineares Codewort (c) umzuwandeln, multiplizieren wir die Nachricht wie folgt (m) mit einer Generatormatrix (G):
$$
c = \begin{bmatrix} m_1 & m_2 & . & m_k \end{bmatrix} \overbrace{\begin{bmatrix} I_k & | & P_{k×(n-k)}\\ \end{bmatrix}}^{G}
$$
Sie sehen dass die Generatormatrix eine Identitätsmatrix (I) und eine Paritätsmatrix (P) enthält. Die Identitätsmatrix stellt sicher, dass m1 bis mk der Quellennachricht im endgültigen Codewort erhalten bleiben (systematisch), während die Paritätsmatrix (P) die Paritätsbits hinzufügt.
Paritätsprüfungsmatrix (H) und Syndrom (s)
Die Paritätsprüfungsmatrix (H) sieht so aus:
$$
H = \begin{bmatrix} P^T_{(n-k) \times k} & | & I_{(n-k)}\\ \end{bmatrix}
$$
Der Empfänger multipliziert das empfangene Codewort (c) mit der transponierten Paritätsprüfungsmatrix – das ist HT, um das Syndrom (s) zu erhalten.
$$
s = \begin{bmatrix} c_1&c_2&.&c_n\\ \end{bmatrix} H^T
$$
Wenn der Syndromvektor nur Null-Einträge liefert, ist das empfangene Codewort gültig.
Hamming-Distanz (dH)
Die Hamming-Distanz (dH) steht für die Anzahl der Bitänderungen beim Übergang von einem Codewort zum anderen. Zum Beispiel würde ein Wechsel von Codewort 010 zu 111 die folgenden Bitwechsel enthalten.
$$
\begin{bmatrix}0 & 1 & 0 \\\end{bmatrix}\rightarrow\begin{bmatrix}\color{red}{1} & 1 & 0 \\\end{bmatrix}\rightarrow\begin{bmatrix}1 & 1 & \color{red}{1} \\\end{bmatrix}
$$
Für das obige Beispiel sind 2 Schritte erforderlich, was einem dH von 2 entspricht.
Formal ausgedrückt ist der Hamming-Abstand (dH) gleich der Anzahl der von Null verschiedenen Stellen nach der XOR-Verknüpfung beider Codewörter in der Berechnung:
$$
\require{enclose}
\begin{array}{r}
010 \\[-3pt]
\oplus\underline{111}\\
101 \\
\end{array}
$$
Es gibt 2 von Null verschiedenen Stellen, das bedeutet (dH) ist 2.
Hamming-Gewicht
Die Mindest-Hamming-Distanz (dmin) ist die kleinste Hamming-Distanz, die nach der Iteration über alle möglichen Paare von Codewörtern besteht. Wenn die Codewörter linear sind, lässt sich die minimale Hamming-Distanz leicht erkennen, indem man das Codewort mit dem kleinsten Hamming-Gewicht betrachtet (ausgenommen solche mit allen Nulleinträgen).
Wie wir sehen werden, ist es möglich, durch die Kenntnis der minimalen Hamming-Distanz die Anzahl der erkennbaren Fehler und auch die Anzahl der Fehler, die korrigiert werden können, zu bestimmen.
Beispiel: Hamming (7,4)
Bei der Anwendung von Hamming(n,k) müssen wir n und k angeben, wobei “n” die Codewortlänge und “k” die Länge der Quellnachricht ist. Diese Begriffe wurden bereits weiter oben erklärt.
Wir wollen also die Nachricht mit k = 4 Bits senden, z. B. 1011, wobei die Codewortlänge (n) auf 7 gesetzt wird. Wir verwenden eine Generatormatrix G wie folgt:
$$
G =
\begin{bmatrix}
1 & 0 & 0 & 0 & 1 & 1 & 0\\
0 & 1 & 0 & 0 & 1 & 0 & 1\\
0 & 0 & 1 & 0 & 0 & 1 & 1\\
0 & 0 & 0 & 1 & 1 & 1 & 1\\
\end{bmatrix}
$$
Wir multiplizieren unsere Nachricht mit G, um unser Codewort zu erzeugen. Zur besseren Veranschaulichung wurden die Paritätsoperatoren grün dargestellt.
$$
\begin{bmatrix}
1 & 0 & 1 & 1\\
\end{bmatrix}
\begin{bmatrix}
1 & 0 & 0 & 0 & \color{lime}{1} & \color{lime}{1} & \color{lime}{0}\\
0 & 1 & 0 & 0 & \color{lime}{1} & \color{lime}{0} & \color{lime}{1}\\
0 & 0 & 1 & 0 & \color{lime}{0} & \color{lime}{1} & \color{lime}{1}\\
0 & 0 & 0 & 1 & \color{lime}{1} & \color{lime}{1} & \color{lime}{1}\\
\end{bmatrix}
=
\begin{bmatrix}
1 & 0 & 1 & 1 & 0 & 1 & 0\\
\end{bmatrix}
$$
Für den Empfänger wäre das empfangene Codewort (c) 1000101 (statt des gesendeten Codeworts 1011010). Wie erläutert, setzt sich die Paritätsprüfungsmatrix (H) aus den transponierten Paritätsbits der Generatormatrix (grün dargestellt) und der Identitätsmatrix (In-k) zusammen.$$
H =
\begin{bmatrix}
\color{lime}{1} & \color{lime}{1} & \color{lime}{0} & \color{lime}{1} & 1 & 0 & 0\\
\color{lime}{1} & \color{lime}{0} & \color{lime}{1} & \color{lime}{1} & 0 & 1 & 0\\
\color{lime}{0} & \color{lime}{1} & \color{lime}{1} & \color{lime}{1} & 0 & 0 & 1\\
\end{bmatrix}
$$
Um das Syndrom zu erhalten, multiplizieren wir unsere empfangene Nachricht mit der transponierten Paritätsprüfungsmatrix (HT):
$$
s =
\begin{bmatrix}
1 & 0 & 0 & 0 & 1 & 0 & 1\\
\end{bmatrix}
\overbrace{
\begin{bmatrix}
1 & 1 & 0 \\
1 & 0 & 1 \\
0 & 1 & 1 \\
1 & 1 & 1 \\
1 & 0 & 0 \\
0 & 1 & 0 \\
0 & 0 & 1 \\
\end{bmatrix}
}^{H^T}
=
\begin{bmatrix}
0 & 1 & 1 \\
\end{bmatrix}
$$
Wenn das Syndrom alle Nulleinträge liefert, ist das empfangene Codewort gültig. Da unser Syndrom nicht alle Nullen enthält, ist unser empfangenes Codewort nicht gültig.
Warum verwendet man lineare Codewörter?
Wir haben bisher die Verwendung von linearen Codewörtern erörtert und wie man sie mit Hilfe einer Generatormatrix erzeugt. Aber warum sollte man lineare Codes verwenden?
Zunächst denken Sie vielleicht, eine Tabelle mit allen Codewörtern wäre ausreichend. Das ist jedoch keine effektive Methode und erfordert Speicherplatz zum Speichern von 2k Codewörtern.
Bei der Verwendung linearer Codewörter müssen wir nur k Codewörter kennen, die als Keimzelle für die Erzeugung aller 2k Codewörter dienen. Bezogen auf die Generatormatrix in unserem Hamming(7,4)-Beispiel:
$$
G =
\begin{bmatrix}
1 & 0 & 0 & 0 & 1 & 1 & 0\\
0 & 1 & 0 & 0 & 1 & 0 & 1\\
0 & 0 & 1 & 0 & 0 & 1 & 1\\
0 & 0 & 0 & 1 & 1 & 1 & 1\\
\end{bmatrix}
$$
Nur die 4 hervorgehobenen Werte in der nachstehenden Tabelle müssen in der Generatormatrix gespeichert werden, die – multipliziert mit der Nachricht – alle 16 Codewörter in der Tabelle reproduzieren kann.
| 24 (16 Codewörter) für das Hamming(7,4)-Beispiel. | |
|---|---|
| 1000110 | .. |
| .. | .. |
| .. | .. |
| 0100101 | .. |
| .. | 0010011 |
| .. | .. |
| .. | .. |
| .. | 0001111 |
Grafische Interpretation von Hamming
Bisher haben wir die mathematischen Berechnungen zur Erzeugung von Codewörtern erörtert. Wenn die Codewörter linear sind, ist es auch einfach, die minimale Hamming-Distanz zu ermitteln, indem man das Codewort mit dem niedrigsten Hamming-Gewicht sucht.
Eine weitere Methode zur Veranschaulichung von Hamming ist die Darstellung von Codewörtern in einem Raumdiagramm. Zum Beispiel:
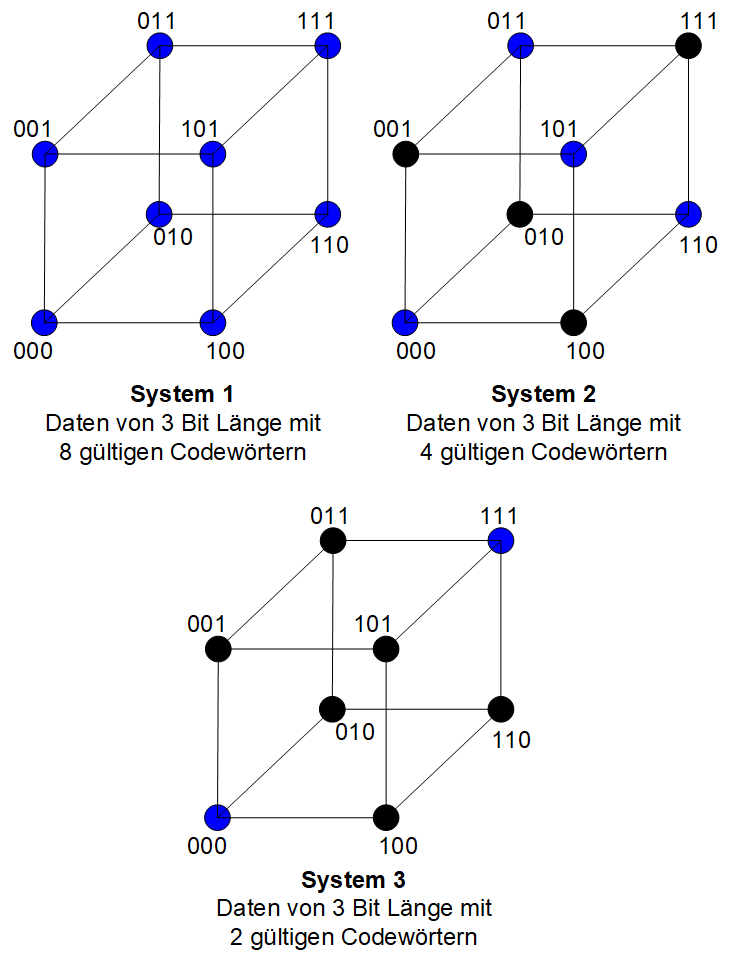
Beispiel für Hamming-Codes
Die Punkte stehen für Codewörter, wobei der Abstand zwischen den Codwörtern jeweils eine Hamming-Distanz ist. Nur die blauen Punkte stellen gültige Codewörter dar, der Rest ist ungültig. Im System 1 sind alle Codewörter im Raum gültig (Hamming-Distanz Eins), so dass wir mehrere Codewörter zur Verfügung haben. Es gibt jedoch keine Möglichkeit der Fehlererkennung, da jede Verschiebung zu einem anderen gültigen Codewort führt. In System 3 sind wir auf nur 2 Codewörter beschränkt, aber die Fähigkeit, Fehler zu erkennen/zu korrigieren, wird höher sein.
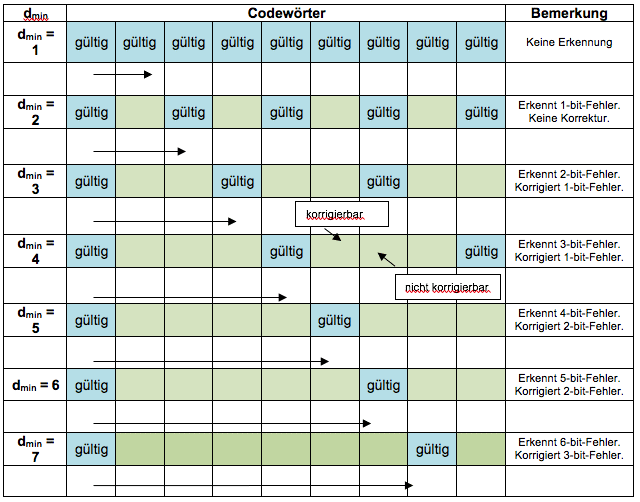
Codewörter in der Reihenfolge ihrer Mindest-Hamming-Distanzen
Die Anzahl der korrigierbaren Fehler ist immer geringer als die Anzahl der erkennbaren Fehler und wird durch die folgenden Formeln bestimmt:
$$
\text{Erkennbare Fehler: }E_d = d_{min} – 1
$$
$$
\text{Korrigierbare Fehler: }E_c = (d_{min} – 1)/2
$$
*Bei korrigierbaren Fehlern: Wenn das Ergebnis ein Bruch ist, abrunden.
Fazit
Die Fehlererkennung und -korrektur umfasst viele Techniken – sie alle erschöpfend zu beschreiben, würde den Rahmen dieses Artikels sprengen. Im Großen und Ganzen lassen sie sich unter Block- oder Faltungskodierung einordnen.
Die Entscheidung über die Art der Fehlererkennung und -korrektur, die für eine zufriedenstellende Kommunikation erforderlich ist, hängt von den Anforderungen der Anwendung ab. Wie bei der Entwicklung entstehen bei der Implementierung von Fehlererkennung und -korrektur in Ihrer Kommunikation Kosten.
Untere effektive Bitrate: An die Quelldaten werden zusätzliche Bits angehängt, was bedeutet, dass die Übertragung der Informationen bei gleicher Bandbreite länger dauern würde.
Bidirektionale Kommunikation: Wenn der Empfänger Fehler erkennt, besteht die Möglichkeit, eine erneute Übertragung anzufordern, was die Einrichtung einer bidirektionalen Funkstrecke erfordern würde. Das erhöht die Komplexität der Hardware. Wenn die Übertragungen jedoch zyklisch sind, können wir fehlerhafte Pakete verwerfen, ohne eine erneute Übertragung anzufordern.
Verzögerung: Wenn der Empfänger die Daten auf Fehler überprüft, muss er Berechnungen durchführen und gegebenenfalls fehlerhafte Bits korrigieren. Jeder Rechenschritt benötigt Zeit, und die dadurch entstehende Verzögerung kann erheblich sein. Die Verzögerung kann nur zunehmen, wenn mehr Berechnungen erforderlich sind. Bei zyklischen Übertragungen ist es vielleicht schneller, die fehlerhaften Daten zu erkennen und zu verwerfen, als sie zu korrigieren.